

비지도 학습:
데이터의
숨은 질서
정답(Label)이 없는 방대한 데이터 세트에서 알고리즘이 스스로 패턴을 발견하고 구조화하는 과정을 탐구합니다. 통찰은 명시적인 지시가 아닌, 데이터 간의 관계 속에서 피어납니다.
패턴 탐색의 가치:
스스로 말하는 데이터
지도 학습이 '선생님'이 있는 학습이라면, 비지도 학습은 원석에서 스스로 보석을 찾아내는 과정입니다. 데이터 포인트 간의 거리와 밀도를 계산하여 유사한 특징을 가진 그룹을 형성합니다.
지능형 매개변수 최적화
K-평균 군집화(K-means)의 초기 중심점 설정부터 최적의 클러스터 개수를 찾는 '엘보우 방식(Elbow Method)'까지, 데이터의 본질적 구조를 파악하는 것이 최우선입니다.
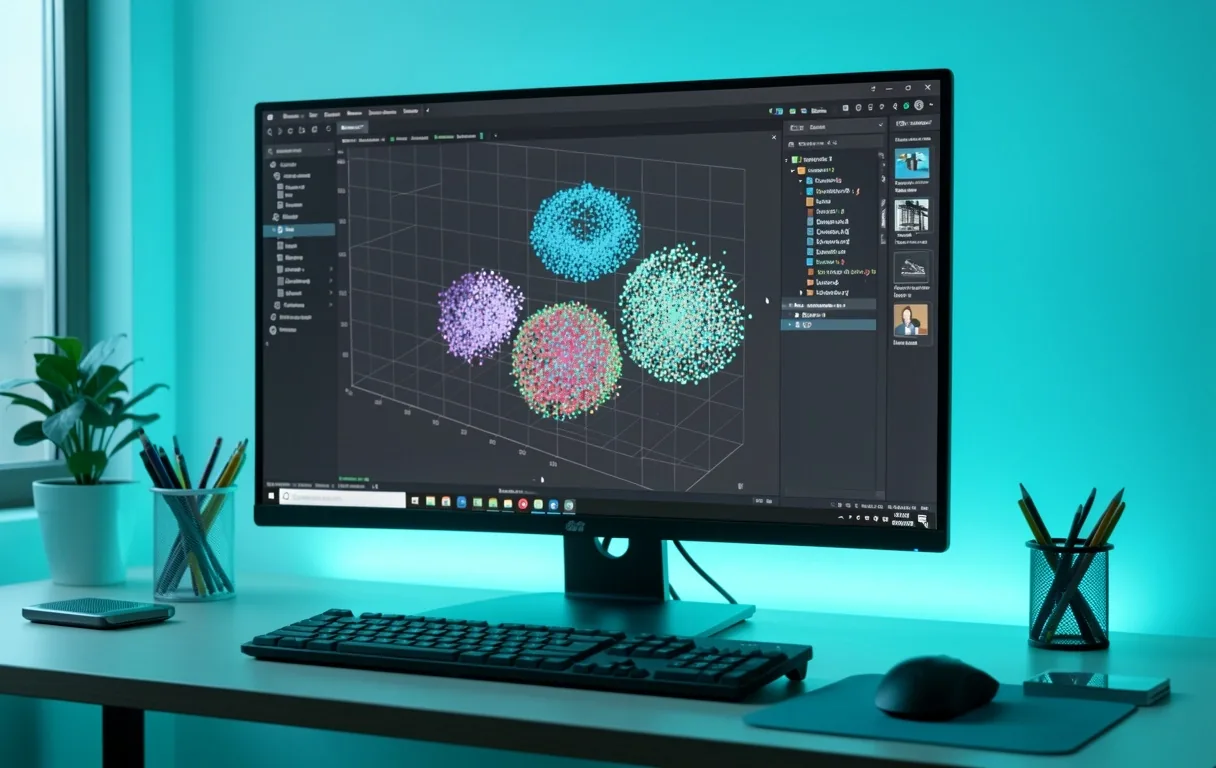
클러스터링 원리
데이터 상관계수
실제 구현 가능성
복잡한 수식 없이도 직관적인 알고리즘 로직을 통해 실무 데이터의 고차원 특징을 추출할 수 있습니다.
방대한 데이터를 핵심 정보로 압축하는 기술
고차원의 데이터를 2차원 또는 3차원으로 투영하여 시각화하거나, 연산 효율성을 높이기 위한 필수 알고리즘 스택을 소개합니다.
K-Means Clustering
가장 널리 사용되는 군집화 알고리즘입니다. 각 데이터 포인트에서 가장 가까운 중심점(Centroid)을 찾아 그룹을 할당하고, 중심점을 반복적으로 갱신하며 최적의 분류를 수행합니다.
- 유클리드 거리 기반 유사도 측정
- 대규모 데이터셋에 대한 빠른 수렴
 Dimensionality Reduction
Dimensionality Reduction
PCA (주성분 분석)
데이터의 분산(Variance)이 가장 큰 방향을 찾아 차원을 축소합니다. 정보 손실을 최소화하면서도 복잡한 다차원 데이터를 직관적으로 이해할 수 있는 형태로 변환합니다.
"고차원 데이터의 기하학적 특징은 주성분을 통해 가장 명확히 드러납니다."
거리 측정 방식
알고리즘의 성능은 '데이터 간의 유사성을 어떻게 정의하느냐'에 달려 있습니다. 맨해튼 거리, 코사인 유사도 등 도메인에 맞는 척도 선택이 필수적입니다.
실행 가능한 정적 코드 설계
UVCNO는 복잡한 의존성 없이 표준 라이브러리 환경에서 작동하는 코드를 지향합니다. 아래의 코드 스니펫은 K-Means의 핵심 로직을 파이썬으로 구현한 정적 예시입니다.
import numpy as np # 1. K-Means 초기화 함수 def initialize_centroids(data, k): indices = np.random.choice(data.shape[0], k) return data[indices] # 2. 클러스터 할당 (거리 계산) def assign_clusters(data, centroids): distances = np.linalg.norm( data[:, np.newaxis] - centroids, axis=2 ) return np.argmin(distances, axis=1) # 3. 중심점 업데이트 def update_centroids(data, clusters, k): return np.array([ data[clusters == i].mean(axis=0) for i in range(k) ])
당신의 데이터에는 정답이 있습니까?
올바른 알고리즘 선택은 프로젝트의 성패를 가릅니다. 목표가 '예측'인지 '탐색'인지에 따라 학습 전략을 수정해야 합니다.
선택 기준 I: 정답(Label) 유무
미래의 수치를 예측하거나 스팸을 분류해야 한다면 지도 학습을, 구매 패턴이나 사용자 행동의 군집을 분석하려면 비지도 학습을 선택하십시오.
선택 기준 II: 데이터 차원의 규모
수천 개의 변수를 가진 데이터라면 시각화를 위해 PCA 등의 차원 축소를 먼저 적용하는 것이 통찰을 얻는 가장 빠른 지름길입니다.

구조를 보는 눈,
인사이트를 넓히다
비지도 학습은 단순한 알고리즘 그 이상입니다. 혼돈 속에 숨겨진 질서를 발견하는 도구이며, 데이터가 가진 무한한 잠재력을 깨우는 열쇠입니다.